
In this guest blog, Osian Llwyd Jones, Head of Product, Data Platform at Stuart, a leading European urban logistics company, shares the experience of his first three months on the job. The original text was written in 2021 when Osian started as Stuart’s data product manager for their internal data platform.
This piece is a rare glimpse – through the practitioner’s perspective – into what it means to sit at the powerful intersection between data and product and why it’s critical for a modern data platform team like Stuart’s to “think product” to truly deliver business value. Osian draws on the challenges he faced when looking at a data platform through a product lens and redefining it from simply a “tech stack” to what it really is: a product that delivers value to hundreds of business users day in, day out. Most importantly, this article serves as a guide to data platform teams at any stage of their “product orientation” and contributes to the emerging space of “data as a product".
The Uncomfortable Questions
In recent years most companies have adopted a data platform as a way to manage how data is ingested, stored, transformed and accessed at scale. The end goal is typically to support the business in making fast and reliable data-driven decisions, and here at Stuart we’re no different.
In the face of exploding volume and complexity of data which needs no further explanation, the focus of data platform teams has understandably been concentrated on stability and reliability at scale. For example, ensuring the smooth running of business-critical pipelines, minimizing downtime, or optimizing query efficiency.
While companies large and small have made considerable gains in building a scalable and sustainable architecture, we’re left with uncomfortable questions: Are data teams truly providing value? Do we really know who our users are and understand their needs? If so, can they generate insights in a fast and reliable way? As long as users don’t complain and pipelines don’t fail, does that mean all is well? For all our investment in data, are we seeing the return?
These questions are particularly difficult to answer for an internal platform that doesn’t make money from its users. Moreover, the added complexity of quantifying the value that data brings forces us to consider alternative definitions of value:
- Top-down: How does the data platform align with and contribute to company goals?
- Bottom-up: Would users choose to use the data platform, and is it easy to use?
While the importance of the former cannot be underestimated and should play a critical part in goal setting and prioritization, this is often a question of modifying process. Meanwhile, the latter is a more complex topic, and especially so for a data platform intended for business (i.e. human) decision-making. To better understand users requires more than a change in process — we need a change in mindset.
When the data platform is viewed purely from a technical lens, we put ourselves at risk of forgetting our users and their needs, and building solutions before we’ve understood the problem and further increasing the data/value gap.
These questions are particularly important to ask now, when the growing discussion around data mesh suggests we’re on the verge of a radical shift in how the business interacts with and governs data. This only increases the need to proactively and continuously understand our users and their evolving needs.
The Data Platform: More Than a Tech Stack
Much in the same way that experimentation platforms, algorithms, and even the data itself are being increasingly considered products, we turn our attention to the data platform. For simplicity, consider the data platform to refer to all the tech and tools that collectively serve the business to make data-driven decisions.
If the previous section wasn’t enough to convince us, there is one concept that helps sum up the need for product thinking for a data platform more than anything:
Accessing and working with data is a user experience.
In the same way we use applications for almost everything in our personal lives from measuring our heart rates to finding a new house, the experience of accessing data to make decisions should be no different. But the concept of UX is rarely heard among data teams. This is hardly surprising if the data platform is viewed entirely as a technical problem and resourced accordingly. To exacerbate the problem, user-facing data tools frequently come with a UI and the assumption lingers that these UIs automatically “take care” of our user needs. In other words, the practitioner’s job is done.
But a good UI cannot replace the need for a good UX. To think that in most modern organizations, hundreds or even thousands of users are interacting with data on a daily basis, the idea of not continuously investing in discovering users’ needs, pain points and desires, of not using this user context to shape our roadmap for success, or more pointedly, of not thinking of our data platform as a product should concern anyone investing in it in the first place.
Here at Stuart the data team is fortunate to sit alongside a strong product team whose philosophy is centered on continuous discovery: identifying opportunities in the form of user needs, pain points and desires and using this to guide our vision, strategy and goals. This means that as well as building products that make sense both from a technical standpoint and aligned with company goals, we’re also strongly led by our users. This approach means we’re more likely to deliver a data platform that users love, and less likely to jump into solutions that ultimately only the platform team loves.
Data Platform as a Product: First Principles
Until now we’ve mostly discussed the why. It’s now time to move from theory to reality and put this into practice: the how. The complex make-up of the data platform doesn’t make it easy to define as a product by any means. Here we present our “first principles” approach, which focused on three broad areas:
- First, at the end of almost all of our data efforts is a user experience. But users are not one and the same; they are diverse and evolving, fast. For this reason we should start by considering our different user personas (“who are our users?”).
- Second, we also need to consider the motives and reasons behind needing a data platform in the first place. We should at least give consideration to user intents (“what do our users want to do with data?”). Similar to use cases but at a much higher level.
- Finally, for the multifaceted data platform we need to make life easy for both our users and ourselves by breaking it down into easily identifiable product components (“how do we present our data platform to our users?”). These components are accessed by users through interfaces, typically representing third-party or internal tools.
Together with other data leads and interviews with key business stakeholders we investigated each of these areas one by one. To ensure it didn’t become a one-off exercise we made them as visible as possible internally (e.g., as part of onboarding a new data or BI engineer). Doing this also incentivizes us to keep the areas relevant and up to date.
User Personas
If we want to shift to a more user-centric approach, understanding who our different users are feels like a logical starting point.
Approach
- If our goal is to provide constant reminders to our data platform teams that there’s a user at the end of our efforts, we need to reflect reality as much as possible. We used names and photos from real users.
- We avoided creating personas directly along job titles or business departments, as it often obfuscates the nuances between teams and is less flexible to change (e.g., a data analyst in one team could have a very different profile to a data analyst in another).
- We tried to at least get a rough number of the size of each persona through looking at usage logs and other documentation. This helps give more meaning and context to a persona.
Outcome

User Intents
Why would anyone make use of a data platform in the first place? What are the key actions our combined user personas should expect to be able to perform autonomously? These were the questions we asked during this step.
Approach
- We placed the word autonomously front and center of this discussion. As we scale we must strive to reduce the dependency on the data platform teams so users can act fast, albeit in an aligned and secure manner.
- With this in mind, we took an aspirational approach in considering both what the user can and cannot do with data by themselves.
- We avoided listing all the specific use cases at this early stage due to the sheer volume of these, which could easily run into several hundreds. Instead, we focused on summarizing high-level intents as described by a single action (verb). As we mature and evolve we can add (and remove) nodes to this “tree” of user intents, possibly then going down to specific use cases.
- As soon as broad categories of user needs emerged we began to group these. For example, the “need right now” vs. “need for future.” The first represents ad-hoc needs for data answers immediately, while the latter represents intents to build or automate in order to avoid repetition in future.
Outcome
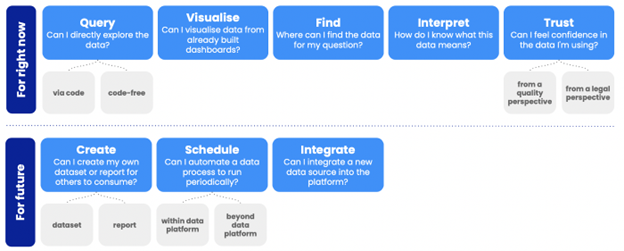
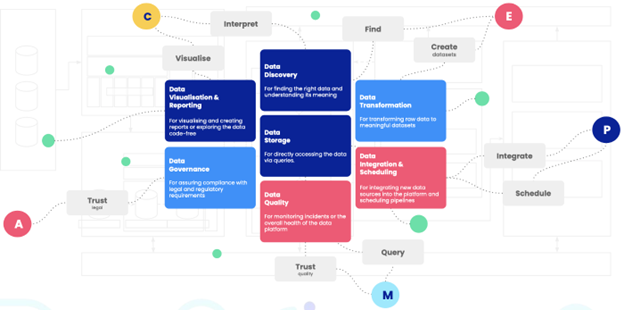
Product Components
With a better overview of the users and motives for using a data platform, we turn our focus inwards and ask what our data platform offers. Similar to how market-facing products sit on a shelf or under the “Our Products” dropdown on a website, how do we represent our data platform as a portfolio of products?
Approach
- We only considered business user-facing aspects of the platform as product components. The goal here is for users to get an easy answer to “What’s in it for me?”
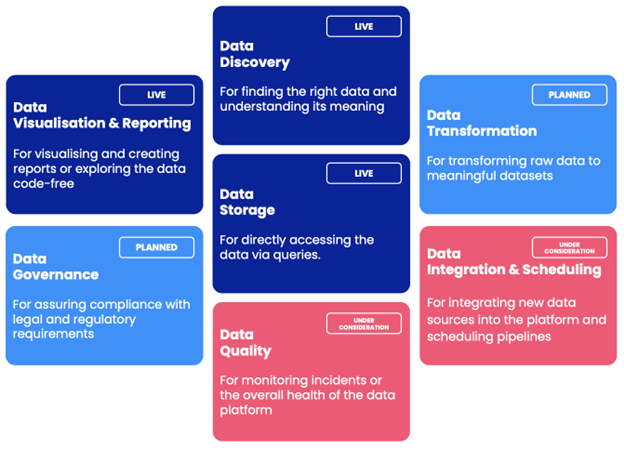
- We divided the platform into components that make sense to our combined user personas. This is an important point, because the purpose of this exercise is not to end with another technical architecture diagram. Components should be named in a way that clearly communicates their purpose.
- Just as for user intents, we shouldn’t be bound only by the current or “live” platform components. Even if there are some that are planned or still under consideration there is no reason not to show them among the components.
Outcome
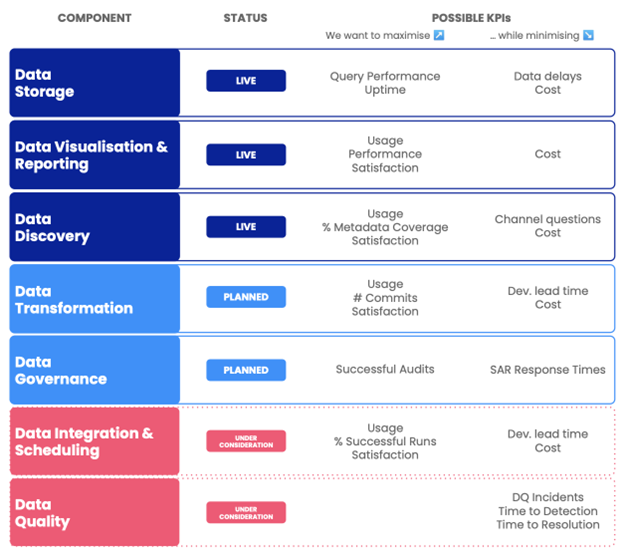
One of the advantages of dividing our platform in this way is that we can build a set of KPIs for each product component, which would then form the basis of future OKRs:
A Note About Interfaces
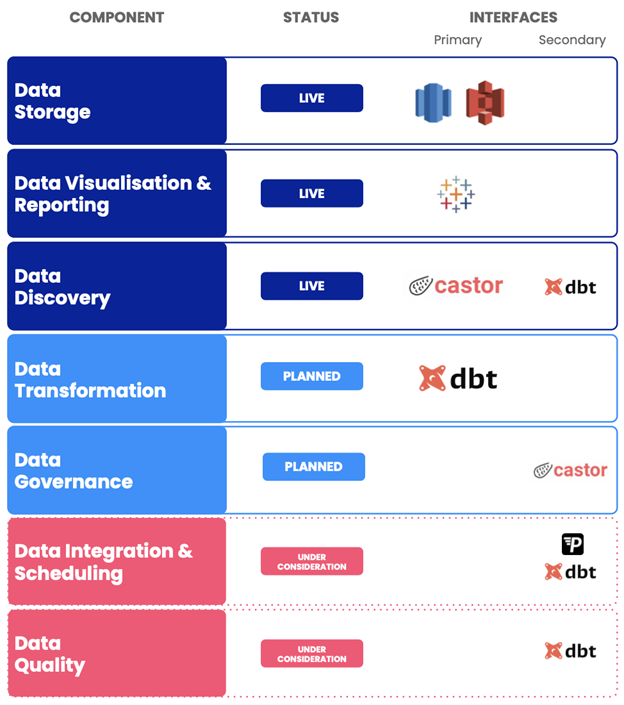
At a later stage, we mapped the more familiar user interfaces (usually third-party tools) to each component, so that users can clearly navigate to the specific tool(s) for accessing each component. We felt it important to distinguish between components and interfaces for these reasons:
- Interfaces change. If we were to replace our primary visualization interface from Tool A to Tool B, the interface has changed but the component remains unchanged.
- Interfaces are increasingly multi-purpose. Many third-party tools are expanding beyond their core offering and some are even considered platforms outright. This means their purpose isn’t always obvious to users. Components help to clarify this. This also means there isn’t a one-to-one mapping of interface to component. For this reason, we introduce the idea of primary and secondary interfaces. The primary interface is where the user should typically be directed. Failing that, the secondary interface may be partially able to serve as that product component.
Connecting the Dots
By taking a step back and linking the use cases, user personas, and components this enables us to:
- Look at our data platform as a manageable set of product components we can measure more easily and build OKRs around.
- Identify gaps in our offering, where important user intents are not linked to a live product component. This is particularly useful as a starting point for building a longer-term strategy.
- Decide how we best organize our teams around common KPIs.
- Structure our roadmap and communications to the business on what we’re delivering, to whom, and why.
Where We’re Heading Next
We’ve introduced the concept of a data platform as a product, moving beyond simply viewing it as a tech stack. We did this by identifying who our users are, their intents, and what our product offering is that can meet those needs.
As we’ve witnessed at Stuart most modern data platforms are complex and multifaceted, so the simple act of putting these on paper and visualizing our platform as a collection of products that deliver value to our users is already a meaningful first step.
Our work is by no means done here — we are only at the start of our journey to becoming more product-led. These practices and principles will form a solid foundation for what comes next: discovering opportunities on an ongoing basis. Opportunities that will play a key role in building our strategy and OKRs for the coming year and becoming a data platform that continuously brings value to our users and to our business.
Main Reading Sources:
- Inspired: How to Create Tech Products Customers Love by Marty Cagan
- “How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh” by Zhamak Dehghani
- “How to Build your Data Platform like a Product” by Barr Moses
- Continuous Discovery Habits by Teresa Torres
Originally published in Stuart Tech.