

Artificial intelligence has quickly become one of the hottest topics in analytics. For all the power and promise, however, the opacity of AI models threatens to limit AI’s impact in the short term. The difficulty of explaining how an AI process gets to an answer has been a topic of much discussion. In fact, it came up in several talks in June at the O’Reilly Artificial Intelligence Conference in New York. There are a couple of angles from which the lack of explainability matters, some where it doesn’t matter, and also some work being done to address the issue.
AI EXPLAINABILITY FROM THE ANALYTICS PERSPECTIVE
From a purely analytical perspective, not being able to explain an AI model doesn’t matter in all cases. To me, the issue of explainability is very similar to the classic problem of multicollinearity within a regression model. I recall having drilled into my head in graduate school the distinction between (1) Prediction and (2) Point Estimation.
If the main goal of a model is to understand which factors influence an outcome and to what extent, then multicollinearity is devastating. The variables that are inter-correlated will have very unstable individual parameter estimates even when the model’s predictions are consistent and accurate. Conceptually, the correlated variables are almost randomly assigned importance. Running the model on one subset of data can lead to very different parameter estimates from another subset. Obviously, this is not good and we spent a lot of time learning how to handle such data to get an accurate answer and also be able to explain it. The point is that multicollinearity made it very hard to pinpoint the drivers of the models, even if the models were extremely accurate.
This is very much like artificial intelligence. You may have an AI process that is performing amazingly well. However, accurately teasing out what factors are driving that performance is difficult. As I’ll discuss later, there is work being done to help address this. But, AI models leave one in a similar spot as multicollinearity did. Namely, a great set of predictions whose root drivers can’t be well explained and specified.
Notice, however, that this issue only matters if you need to explain how the answer is derived. Multicollinearity is not a problem if all you care about is getting good predictions. If the individual parameters don’t matter, then model away. The same is true with AI. If you only care about predicting who will get a disease, or which image is a cat, or who will respond to a coupon, then the opacity of AI is irrelevant. It is important, therefore, to determine up front if your situation can accept an opaque prediction or not.
WHAT’S BEING DONE TO MAKE AI MORE EXPLAINABLE?
As one would expect, there are a lot of smart people working to develop ways to help determine what’s really driving an AI model under the hood. One of the most interesting examples I’ve come across is a process known as Local Interpretable Model-Agnostic Explanations (LIME). What LIME does is to make slight changes to input data in order to see what the impact on the predictions ends up being. Repeat this many times and eventually, you get a good feel for what is really driving a model. See the picture below from the above linked LIME article to get an understanding of what we’re talking about.
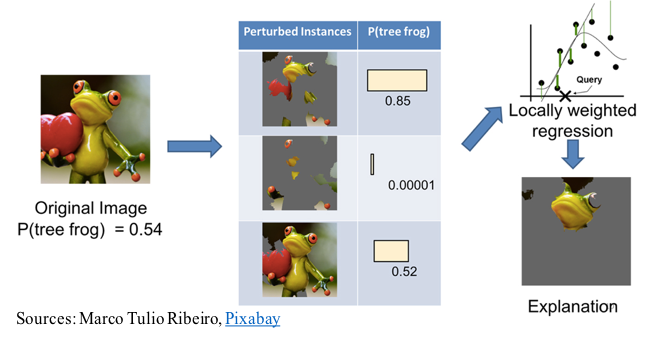
In this case, you can see that the upper face and eyeball subset at the top of the image has a strong influence in the model determining that this is a frog. Some of the other information in the picture actually causes the model to do worse. For instance, the heart being held in his hand certainly wouldn’t be typical of a frog.
While this example focuses on image recognition, a very similar process could be used with a problem based on classic data. For example, the difference in predicted response probability for a customer could be examined as input variables are perturbed in different combinations. Certainly, this isn’t quite as satisfying as a classic parameter estimate. But, it does take AI a long way towards being understood.
Note also one very important point about LIME, which is the “model agnostic” component. LIME really has nothing directly to do with AI and doesn’t know what AI is or does. It is simply a way to take a predictive algorithm and test out how different data causes changes. Therefore, it can be applied to any situation where there is a need to add transparency to an opaque process. It can even be used in situations where firm parameter estimates do exist in order to validate how well it works.
THE PROBLEMS THAT WON’T GO AWAY
No matter how neat LIME might seem, it isn’t good enough to pass muster with laws and regulations. In many cases, such as credit scoring and clinical trials, amazing predictions mean nothing in absence of clear explanation of how the predictions are achieved. As a result, we’ll have to examine our laws and our ethical guidelines to determine how they might be altered to allow AI to be utilized effectively while still keeping the proper checks and balances in place. We are certain to have AI that will be capable of solving very valuable problems sooner than we’ll be allowed to actually put those models to use. It will be necessary to find the right balance of laws, ethics, and analytics power so we can make progress. But, that’s a topic for another blog!
For now, if you’re considering using AI as it exists today, just make sure that what you really care about is simply a solid model that predicts well. If you actually have to be able to explain how the model works and what drives it, you should stick to more traditional methods for the foreseeable future.