
Modern life has been good for those who understand and can develop analytics. From sexto soccer, data and algorithms are having an increasing impact on how important decisions are made. This has led to rapidly-growing employment for those with analytical talents, and even a proclamation that data scientists are the sexiest job of the 21stcentury (don’t blame me, blame my editor—though I admit to signing off on the subtitle).
But it hasn’t been as pleasant for those who don’t understand algorithms but are still subject to the decisions they help to make. The work of quantitative analysts and data scientists is often impenetrable to ordinary mortals. If those subject to algorithmic outcomes question why a decision is made, they might (though probably not) be shown an equation that they don’t understand. They are expected to trust that the algorithm is fair, that the variables or features in it are the right ones, that the data is accurate, and that an information system correctly deploys the algorithm. Those assumptions are often violated, but it may be difficult or impossible for those affected to figure out when they have been.
There’s a great long-form story about this problem by Colin Lecher in The Vergecalled When an Algorithm Cuts Your Health Care (brought to my attention by Jana Eggers, CEO of Nara Logics). It’s about Tammy Dobbs, a woman in Arkansas with cerebral palsy whose home healthcare help was cut substantially because of a machine learning algorithm. She was interviewed by an assessor, provided answers to a set of questions, and found out later her care was being cut back.
Brant Fries, a professor and researcher who heads the organization that developed the algorithm, is undoubtedly a smart quant, and it’s fair for him to defend his group’s algorithm by saying that there needs to be a fair basis for allocating scarce healthcare resources. He’s president of a collaborative organization from which the algorithm is sourced—InterRAI—that is “committed to improving care for persons who are disabled or medically complex.” But it didn’t improve care for Tammy Dobbs.
First, the algorithm was complex, and Tammy Dobbs couldn’t get access to it—and she probably couldn’t understand it if she could have. Second, no one could tell her why the algorithm decided her care benefits should be cut. Fries, who admitted that the algorithm was complex, told the reporter that “you’re going to have to trust me that a bunch of smart people determined this is the smart way to do it.”
A Legal Aid attorney, Kevin De Liban, didn’t trust the smart people, and filed suit in Arkansas courts to address the issue. It turned out that his and Ms. Dobbs’ suspicions were warranted; there were some errors in how the algorithm was implemented, and one of them involved cerebral palsy. Dobbs ultimately got her care hours restored, at least for the moment.
The reporter asked Fries whether algorithms for something so important should be explainable; he clearly wasn’t too bothered about the issue:
Fries says there’s no best practice for alerting people about how an algorithm works. “It’s probably something we should do,” he said when I asked whether his group should find a way to communicate the system. “Yeah, I also should probably dust under my bed.”
Professor Fries, and many other quants and data scientists, had better start caring about the explainability issue. It’s far more important than dusting under the bed. Consumers and their lawyers are increasingly realizing that algorithms drive decisions that make a big difference to their lives, and they want an explanation of them. In European Union, citizens are guaranteed the “right to an explanation”by GDPR regulations, and it’s likely to spread to other geographies.
Of course, providing explanations for algorithms isn’t easy, and it can be extremely challenging for some types of machine learning like deep learning-based image recognition algorithms. Although there is some progress being made toward explaining them—typically with sensitivity analysis approaches like LIME—companies that can’t open up the “black boxes” may simply not be able to use them for decisions with substantial impact on humans.
For more conventional analytics and machine learning models, it’s generally not that hard to shed some light on the algorithm if you’re so inclined. A great example is one of the earliest popular machine learning models: that for scoring your credit. For many years now, Fico—the originator of credit scores—has provided an explanation for what factors affect an individual’s credit score, and what weight is attached to each variable/feature. While Fico doesn’t give details on how each variable is assessed, the weights in the graphic below are pretty useful to anyone trying to understand or improve their score:
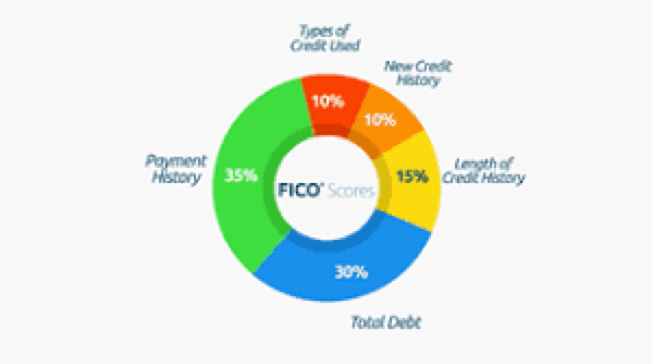
This is increasingly going to become the minimum level of explainability in algorithmic models that have important effects on consumers. If you create an algorithm within your organization that falls into that category, you might want to begin persuading your business partners that it makes sense to shed some light on how it works. It’s far better to get ahead of the desire for an explanation than to face it in court or the press.