
Nuances and Considerations for Implementing Data Mesh
A data mesh architecture distributes data ownership across domain teams with federated governance and decentralized data products. Data mesh contrasts with other data architectures because it is highly decentralized, and distributed as opposed to centralized.
Observations
Many large enterprises that I talk to study data mesh. They find the scaling model of teams taking accountability for their data and adding business value an elegant approach. They enjoy a data product management mindset. However, they do not like the idea of embracing a fully decentralized architecture, which could result in data duplication when joining data, repeated efforts of platform management, creation of silos, and proliferation of technology standards. Other enterprises fear the costs and decreased performance of combining data from multiple teams or are frightened by the need for deep expertise for complex system management: building a decentralized architecture that is controlled via centralized governance is seen as too complex.
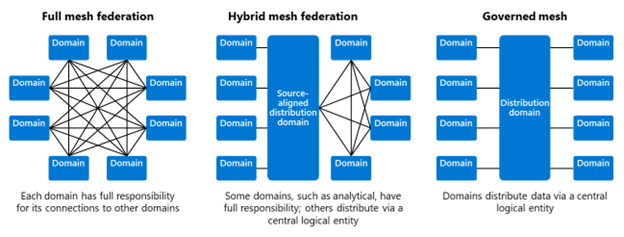
Proposing a Reference Design
Based on these customer conversations, I often propose an alternative by taking some of the principles of data mesh.
Enterprises Enjoy Strong Data Ownership
Putting accountability where data is produced is one of the good things about data mesh. It decentralizes the responsibility of data and puts accountability close to where data is produced. This alignment makes sense because data producers are experts on their own data. They know how their systems are designed and what data is managed inside these systems. They often work closely with end-users or business analysts and therefore know what good data quality means to data consumers. When assigning data ownership and identifying domains, my recommendation is to look beyond applications and systems. Look at the scope and understand the business problem spaces you are trying to address. This analysis includes data, processes, organization, and technology within a particular context, aligned with the strategic business goals and objectives of your organization. When defining domains, ensure that boundaries are distinct and explicit. This is critical because different teams might try to claim ownership of the same applications and data.
Data Product Thinking Resonates Very Well
Another concept that resonates well is data products. Managing and providing data as a product is not the extreme of dumping raw data, which would require all consuming teams to perform repeatable work on data quality and compatibility issues. It also is not the extreme of building an integration layer, using one (enterprise) canonical data model with strong conformation from all teams. Data product design is a nuanced approach of taking data from your (complex) operational and analytical systems and turning it into read-optimized versions for organizational-wide consumption. This approach to data product design comes with lots of best practices, such as aligning your data products with the language of your domain, setting clear interoperability standards for fast consumption, capturing it directly from the source of creation, addressing time-variant and non-volatile concerns, encapsulating metadata for security, ensuring discoverability, and so on. More of these best practices can be found here.
Reservations to Decentralization
When it comes to equipping domain teams with engineering tools for performing the tasks of data product creation and platform ownership, enterprises make different trade-offs. Not all organizations have 500+ data engineers. Not all organizational teams are familiar with complex data modeling techniques, change data capture, Kubernetes, and Python notebooks. Companies demand different approaches depending on their size, business needs, and existing architecture.
Many enterprises I talk to have implemented hub-spoke network topology architectures with centralized platform teams managing all common infrastructure, including data platforms. For generic data services, enterprises often use enabling teams that work closely with other teams for onboarding or consuming data. The data product mindset requires teams to take ownership of data, which includes troubleshooting, fixing data quality issues, and addressing ingestion issues. However, when it comes to complex engineering, there is a maturity curve, and enabling teams often help with onboarding data, training, and guiding teams on best practices. These enabling teams sometimes even take ownership of data pipeline management when a domain team lacks necessary skills.
The same maturity curve typically arises on the data-consuming side. Teams often rely on a shared pool of resources to provide knowledge and help with configuration, ingestion, and transformation of their data. The enabling data team takes the lessons learned and makes improvements to enhance services, such as the framework for data pipelines and ingestion, to make them more dynamic and configurable. It’s a constant balance between addressing inefficiency and applying self-services versus time spent on helping to onboard new data products.
Reference Model with Less Decentralization
For addressing data duplication concerns, enterprises often choose one central data distribution platform over many deployed logical components that are managed by individual teams. This is also where I see many overlaps with data lake house architectures. A reference model showing such an architecture with a single platform instance and data product ownership is provided below.
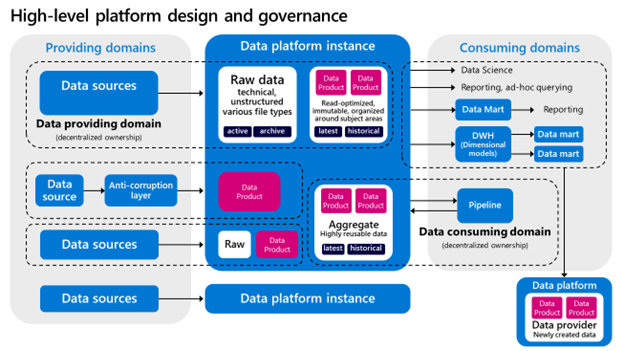
This reference design is a domain-oriented architecture. Although a shared platform is used, either a data providing- or consuming domain takes ownership of data. The data ownership also holds true for data products derived from newly created or aggregated data. There is no central or shared integration layer that merges all data. To address data inconsistency challenges, you can consider introducing master data management principles.
A solution design for such an architecture might look like this:
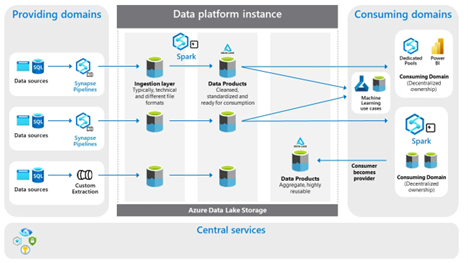
For this architecture, I recommend using a metadata-driven ingestion framework: a uniform, generic way of data processing. Via this control framework, you can establish proper data ownership, which means teams distributing data will always take ownership of their source systems, metadata configuration, pipelines, and data products.
For the consuming side, I advocate for decentral data ownership as well. This means teams working on their use cases will take ownership of their transformed data and analytical applications.
In this architecture, there is one logical storage layer that brings data together from many different teams. This environment acts as a decoupling point between all teams when distributing data products. Segmentation and isolation in such an environment typically take place by using containers per domain. However, you can also logically group domains using storage accounts based on the cohesion you discover. Data in this layer is immutable and read-optimized. Depending on how you want to scale, you can provision additional platform instances.
To support your data domains, there must also be a set of robust data management services for supporting data ingestion, processing flow orchestration, scheduling, managing master data management and data life cycle management, performing data governance and quality management, and addressing security management.
The higher degree of centralization in this model addresses concerns like 1) traveling through large historical datasets without the need for bringing over data from one domain to another domain, 2) allowing to check the degree to which the data are logically connected and mutually consistent, 3) allowing master data management to run more efficiently, and 4) reducing costs by sharing compute resources between different teams. At the same time, it applies several best practices from data mesh, such as data product thinking, domain-oriented data owners, self-serve functionality, and data governance.
In conclusion, every enterprise has its own data landscape and challenges to address. Not all enterprises are ready for decentralization at scale. However, you can strike a balance by choosing a topology that matches your requirements.
Originally published in Towards Data Science.